테슬라 주가 데이터를 이용해 LSTM(Long Short-Term Memory) 모델을 학습시키고, 이를 통해 주가를 예측하는 과정입니다.
주가 데이터셋은 https://www.kaggle.com/datasets/varpit94/tesla-stock-data-updated-till-28jun2021을 사용했습니다.
1. 라이브러리 및 데이터 설정
2. 파라미터 설정
3. 데이터 준비
4. 모델 정의 및 학습
5. 모델 학습 함수 정의 및 학습 수행
6. 모델 평가 및 예측
7. 손실 및 예측값 시각화
1. 라이브러리 및 데이터 설정

2. 파라미터 설정

3. 데이터 준비


4. 모델 정의 및 학습

5. 모델 학습 함수 정의 및 학습 수행

6. 모델 평가 및 예측

7. 손실 및 예측값 시각화

<실행 결과>
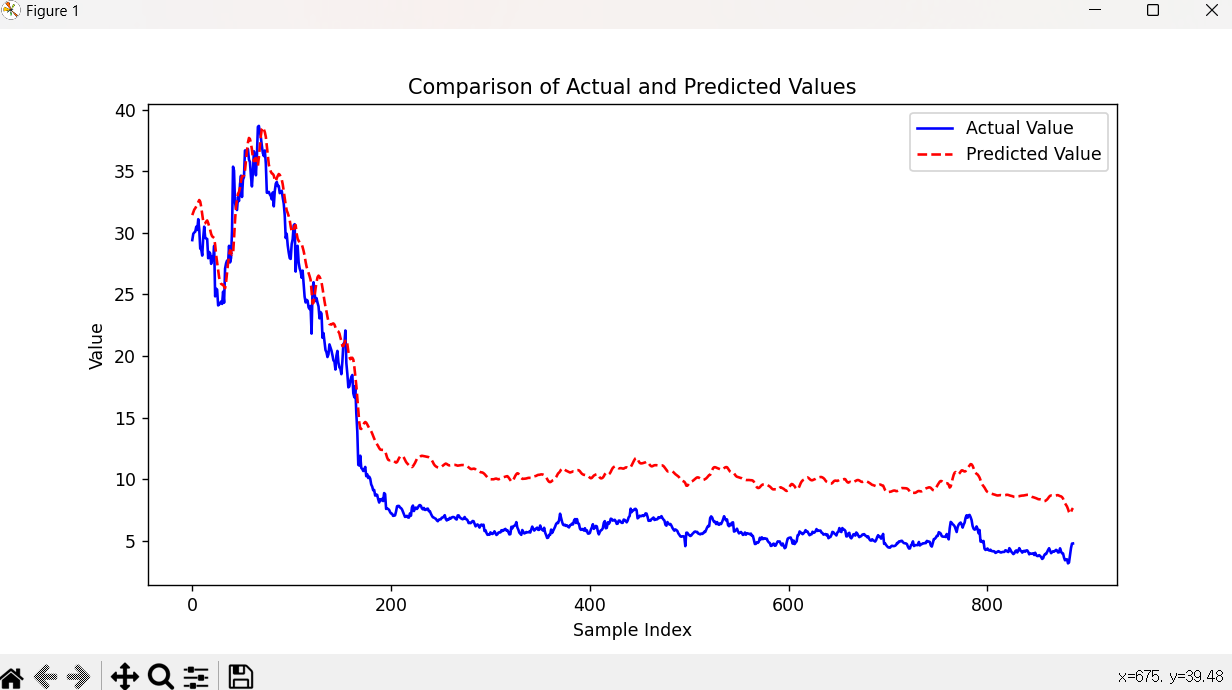
- 초기 구간 (0~100):
- 실제 주가 값과 예측된 주가 값이 비교적 잘 맞아떨어지고 있습니다. 두 값이 거의 일치하며 모델이 이 구간의 주가를 잘 예측하고 있음을 보여줍니다.
- 중간 구간 (100~300):
- 예측된 주가 값이 실제 주가 값보다 높게 나타나고 있습니다. 이 구간에서 모델의 예측이 실제 값보다 높게 나타나는 경향이 있습니다.
- 이 부분에서 모델이 약간의 과적합이 있거나, 학습 데이터와 테스트 데이터의 분포 차이로 인해 발생할 수 있습니다.
- 후반 구간 (300~900):
- 예측된 주가 값과 실제 주가 값의 차이가 지속적으로 발생하고 있습니다. 특히, 예측된 주가 값이 전체적으로 실제 주가 값보다 높게 유지되고 있습니다.
- 이는 모델이 주가 하락을 충분히 반영하지 못하고 있음을 나타냅니다.
모델이 초기 구간에서는 비교적 잘 예측하고 있지만, 중간과 후반 구간에서는 실제 값보다 높게 예측하는 경향이 있습니다. 예측한 주가 값을 실제 주가 값과 더 유사하게 만들기 위해 모델의 하이퍼파라미터 튜닝이나 더 많은 데이터를 사용하여 학습하거나, 데이터 전처리 등을 통해 모델의 성능을 개선할 수 있는 방법을 찾아야할 것 같습니다.
'study' 카테고리의 다른 글
| Google Trends 데이터 요청 에러: 429 (0) | 2024.11.23 |
|---|---|
| 검색량을 이용한 주가예측 (0) | 2024.11.20 |